IA RAG con Ollama y Vector DB

El problema
Un cliente de la industria automotriz recibe leads con datos inconsistentes, los cuales requieren trabajo manual de filtrado, reubicación y programación frecuente de queries.
Por ejemplo: en el campo Modelo a veces se indica la cuota de financiación, en el campo OBS se vuelca sin criterio uniforme mucha información vital, etc

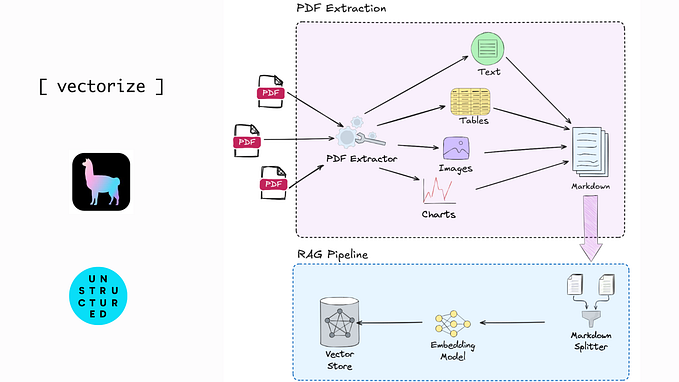
Solución #1 Crear un RAG con Ollama, Pandas y LanceDB

- Importar el CSV a un Vector Database
- Montar un LLM local con RAG (Retrieval-Augmented Generation)
- Escribir un script Python para chatear usando el contexto del Vector Database
Ahora, en lugar de analizar cada fila manualmente, reubicar datos y escribir consultas SQL, es posible interactuar en lenguaje natural solicitando, por ejemplo:
“Listar los mejores contactos de condición autónomo que buscan X modelo de auto”
¿Por qué un Vector Database?

Un Vector Database utiliza algoritmos de búsqueda de similitud, como nearest neighbor search, para recuperar los vectores más cercanos a una consulta dada y permite generar fácilmente el contexto — ordenado y estructurado -para el LLM.
Demo del RAG con Vector Database
Tecnologías utilizadas
- Ollama
- LanceDB
- Modelos qwen2.5 y bge-m3
Detalles a tener en cuenta
Es preciso usar un modelo capaz de usar embeddings. En la página de Ollama es posible filtrar los modelos embeddings con este link
Otras opciones de RAG

Otra opción analizada fue PandasAI “una plataforma que simplifica realizar preguntas a tus datos en lenguaje natural”
Dicho esto, la instalación de PandasAI da error a menos que se haga un downgrade a Python 3.11 Luego, es preciso un API Key https://app.pandabi.ai o bien configurar la API de OpenAI.
Es posible agregar semántica explicando qué es cada planilla y columna, por medio de
pai.create(path=”…” description=”Base de datos de call center con leads para planes de compra de autos 0KM”,
df = file_df,
columns=[
{
“name”: “ID”,
“type”: “integer”,
“description”: “ID del lead”
},
{
“name”: “FECHA_ALTA”,
“type”: “string”,
“description”: “Fecha del contacto con el lead”
},
Funcionó relativamente bien para datos estructurados, pero tuvo dificultades para operar con datos desordenados e inconsistentes en un campo de texto Obs.